Gambling with language models
One clueless investor's attempt at beating the stock market with ModernBert

I began this blog post between two other re:Invent attendees en route to Las Vegas for AWS re:Invent. It's been a while since my last blog post, but I am excited for this one, because I am approaching Vegas with a bundle of optimism. I am prepared to gamble. Blackjack? Slot machines? Poker? Not this year. This year, I join the ranks of the great r/wallstreetbets legends preparing to pick stocks. These stocks, I might add, belong to companies I have never heard of in industries I know little about, and I have no stock trading experience to speak of.
Nonetheless, over the last year or so, in my scant free time, I have slowly begun outsourcing my gambling strategy to machines in Amazon Web Services' data centers.
It is re:Invent, and so I will be utilizing AWS's new and existing machine learning services in the experimentation process. I will also be pulling $5,000 out of my investments and placing them into stocks selected by my machine-learning driven stock-picker. I’ll then revisit my blog post portfolio next re:Invent to see how I did.
By the time I publish this, re:Invent has been over for almost a month. To keep things current, I've adjusted some minor portions of my approach to leverage some new innovations by AWS, Google, and in the open source language model world. The broad strokes, however, remain the same.
Without further ado, let's put Amazon Bedrock, AWS Sagemaker Studio, PyTorch, Hugging Face Transformers, and some open-source models to the test.

Background
There are many approaches to picking stocks, but I enter the realm of finance absent any pre-conceived notions (or idea) of how things should be done. As such, rather than relying on my own reasoning skills, I rely heavily on the reasoning capabilities of language models, and their ability to extract knowledge, understand text, and predict quantitative outcomes.
I should also point out, that one last major change I made to this blog post over the last two weeks. Following an exciting new release by the answer.ai and LightOn teams, I switched to fine-tuning ModernBert, a long-context, SoTA encoder-only model to predict stock prices. This type of model was exactly what I had searched for when first starting the project to no-avail.
By the end of this blog post, a fine-tuned version of ModernBert-large becomes the brains of my fledgling stock-picking operation.
The remainder of this blog post is dedicated to providing a detailed description of my process, along with accompanying code snippets to explain the various steps I undertook in this experiment. It also explains the anticipated results, and my hypothesis that even a model that predicts stock price with a substantial error rate might enable me to do better than randomly picking stocks or purchasing an index fund.
Methodology
At 1000 feet, my methodology was to synthesize a broad range of information about publicly traded companies, process it, and then train a model to predict stock growth for each of these companies. I then leveraged the most recent company information to predict future growth for each of these stocks using the trained model, and ranked the stocks in order of best predicted performance.
It's important to note that I am not relying on precise predictions of future stock prices for any given company. After all, even if I had access to the a structured data corpus of the companies internals, stock prices are impacted by events that have not yet come to pass. As such, rather than attempting to look into a crystal ball, I'm aiming to create a system that, by looking at a rich context of financial reports, macroeconomic indicators, and more, can produce a relative ranking of which stocks should perform better than others.
While still within the realm of divination, my predictions are more murky, akin to reading tea-leaves rather than being crystal-ball clear. The idea is that, even if the model’s absolute predictions are inaccurate, the relative rankings might provide an edge in selecting a portfolio that outperforms the market.
As an input to my model, I processed data to generate what I call "contextual snapshots." These snapshots act as a rich, time-bound report cards for each company at a given fiscal quarter. Each snapshot is a combination of financial statements, analyst reports, macroeconomic factors and more, distilled into a report that the model can learn from. Think of it like a time capsule for each company, encapsulating a wealth of information for each historical quarter and year.
My hypothesis is that, after being exposed to these capsules a model might identify patterns that an untrained eye might miss within these contextual snapshots.
With high level methodology out of the way, let’s dive into some details of each phase: the data preparation, the model training, and finally, the stock ranking.
Data Preparation
A cloud-based experimentation environment
Prior to training a model, I needed to gather, clean, and format the necessary data. Like many a data scientist, I depend heavily on Jupyter notebooks for interactive feedback. Unfortunately, my laptop and network doesn't have the horse-power necessary to handle the scraping, text processing, and model training requirements without impacting my day to day work.
Enter AWS SageMaker Studio notebooks. Sagemaker Studio notebooks are cloud-based and allow you to stop and start jupyter notebook instances as needed. I started with a t3.medium instance for data fetching and light processing. I found this instance to be more than adequate for those initial tasks. This instance type, though not GPU-enabled, provided enough power for data download, and text manipulation.
One of the things I like about Sagemaker Studio notebooks is that it's super easy to swap out the compute for something with a little more horse-power if you need to later on. (I knew I'd need something a little more beefy for the model training portion.)
I will add that since starting this project, AWS has released a preview for Sagemaker Unified Studio. A new product that aims to more seamlessly integrate AWS's individual data-engineering components to provide an end-to-end data engineering platform. Check it out if you're looking to do something production ready.
Gathering Financial Data
My first step was to download the current holdings of the Russell 3000 index, to create a list of the stocks I would be focusing on.
Then, I used this sec-cik-mapper library to map company ticker symbols to their unique SEC CIK identifiers (a critical step to accessing filings).
After consulting with my personal finance expert, Claude 3.5 Chat, I discovered the SEC's Edgar database, along with the Federal Reserve Economic Data (FRED) and Bureau of Economic Analysis (BEA) APIs were some accessible and free sources I could use to gather the micro-economic data for these companies and macro-economic data surrounding the time-periods in question. I also discovered that I could use the finagg tool to easily access the data from these APIs. So I started forming historical profiles for each of these companies from all of these data sources.
Additionally, I downloaded historical financial filings, specifically 10-K (annual reports) and quarterly 10-Q filings which provide detailed insights into each company's financial health. From these reports, I extracted two critical sections: Risk Factors, and Management's Discussion and Analysis (MD&A). These are often long, dense, and might contain information necessary to contextualize a company's current state. It might also contain some intent signals that machine learning models might pick up embedded in the report writing style and choice of words that might not be captured by human readers.
To parse these documents, I leveraged an approach I discovered in this gist. (I might add that if you like any of the open source code or tools I depend on, you can show your support by starring them on github!)
import re
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
def parse_10_k(text, hash_digest) -> Form10KExtracts | None:
# Regex to find <TYPE> tags followed by section names like '10-K'
sections_regex = re.compile(r'(>(Item|ITEM)(\\s| | )(1A|1B|7A|7|8)\\.{0,1})')
matches = sections_regex.finditer(text)
matches_list = [(x.group(), x.start(), x.end()) for x in matches]
# Check if we have any matches before creating DataFrame
if matches_list:
sections_df = pd.DataFrame(matches_list, columns=['item', 'start', 'end'])
sections_df.columns = ['item', 'start', 'end']
sections_df.replace(' ',' ',regex=True,inplace=True)
sections_df.replace(' ',' ',regex=True,inplace=True)
sections_df.replace(' ','',regex=True,inplace=True)
sections_df.replace('\\\\.','',regex=True,inplace=True)
sections_df.replace('>','',regex=True,inplace=True)
sections_df['item'] = sections_df.item.str.lower()
sections_df.sort_values('start', ascending=True, inplace=True)
deduped = sections_df.drop_duplicates(subset=['item'], keep='last')
deduped.set_index('item', inplace=True)
risk_factors = clean_string(get_text_only(text[deduped['start'].loc['item1a']:deduped['start'].loc['item1b']]))
md_and_a = clean_string(get_text_only(text[deduped['start'].loc['item7']:deduped['start'].loc['item7a']]))
return Form10KExtracts(risk_factors, md_and_a, hash_digest)
else:
return None
Prompt Engineering for Financial Analysis
Because the extracted sections from the reports tend to be long and verbose, it would have been infeasible to directly use them as input to my model. Instead, I employed the power of large language models to create summaries of these sections. For my initial inferences of the model I used Claude 3.5 Haiku over Amazon Bedrock. This was an awesome experience when I first started out, as the api is much more reliable than many others.
Then a couple of months ago, (I think around the same time that Bedrock introduced batch inference into GA) Bedrock started imposing some pretty onerous usage quotas. I didn't want to rearchitect my process to be event driven since a more synchronous experience is desired for my experimentation. As such, when I processed the most recent batch of documents in preparation for pulling the trigger on this experiment and publishing this blog post, I pointed to Google's Gemini 2.0 experimental API which did well enough.
Prior to switching off of bedrock, I tried using the new Nova Micro model and I found that while it was able to understand a lot, it wasn't as good at claude or gemini at following instructions and while it's quota was higher than the Haiku quota, it was still very limited. You might still see some remnants of this experimentation in the source code. (I will paste a link at the end of the blog post in case you're interested)
Here’s one example of one instance where Nova micro wasn't able to reliably give me meaningful output in my requested format:
In each company's us-gaap filings, they include sometimes hundreds of keys describing their financial situation. Processing them all is a fools errand, and each company uses different keys. So I asked Gemini to select the ones that would be most useful for a financial analyst:
keys = ['AccountsPayableAndAccruedLiabilitiesCurrent', 'AccountsReceivableNetCurrent', 'AccruedIncomeTaxesCurrent', 'AccumulatedDepreciationDepletionAndAmortizationPropertyPlantAndEquipment', ...]
key_string = '\\n' + '\\n* '.join(keys)
context_information = [f"In this companies us-gaap report, the following keys are available: {key_string}"]
prompt = GeminiPrompt(
task="Select 20 keys from the us-gaap keys provided in the context to enable a financial analyst to quickly make a snap-judgment of the company's performance.",
context_information=context_information,
instructions=["Be thorough in your analysis and ensure the keys you select are categorical, distinct, non-overlapping and represent key financial indicators like profits, revenues, assets, liabilities, and investments in company growth. Ensure the keys summarize the company's financial health effectively and are present in the context information."],
response_format_instructions=["Respond with only a markdown code block containing a json list of strings representing the selected keys: eg. ```json\\n[\\nKey1,\\nKey2\\n,...,Key10\\n]\\n```", "Verify the presence of each of the keys in the provided context before responding", "Preserve the original PascalCase of the keys eg. 'AssetsCurrent' rather than 'Assets Current' and 'CostOfGoodsSold' instead of 'Cost Of Goods Sold'", "Order the keys in the order of importance"]
)
response = get_gemini_response(prompt, output_format="json")
While Gemini and Claude 3.5 Haiku do a decent job of this, I found that getting Nova-micro to respond in a deterministic format difficult.
Similarly, I used prompts to summarize the risk factors and the management discussion and analysis (MD&A) section, keeping the same careful eye on structured prompts that minimize hallucinations and ensure correct formatting.
Note that I also didn't want the model to favor companies based on identifying information withhin my snapshots so I instructed the model to redact company specific information:
redaction_instructions = "Any time the company's name, or year of the report, or any revealing product name would appear in the returned markdown document, redact it using the tag [REDACTED] so that a reader would not know which company is described. Also ensure summaries and quotes do not include names of individuals associated with the company."
def summarize_risk_factors(risk_factors: str):
context_information = [f"The following text was scraped from the risk factors section of a company's 10-K report: ```\\n{risk_factors}\\n```\\n "]
task = "Return a three paragraph summary of the most important information for a financial analyst to understand the company's risk factors. Also include a set of up to ten quotes from the text that support the summary."
response_format_instructions = [f"The summary should be formatted as a markdown file with a 'Risk Factors' heading with two sections: Summary and Substantiating Quotes. {redaction_instructions}", "Respond only with a markdown code block containing markdown content within starting '```markdown\\n' and ending: '\\n```'"]
prompt = GeminiPrompt(
task=task,
context_information=context_information,
response_format_instructions=response_format_instructions
)
response = get_gemini_response(prompt, output_format="markdown")
return response
Aside from Risk Factors and MD & A sections, I spent a bit of time trying to summarize the huge Disclosures sections as well, but it was taking too long and outside of my token budget (probably because companies like to bury their important disclosures in mountains of irrelevant text in the hope that nobody will notice).
Creating the Contextual Snapshot
The culmination of the data preparation process was the creation of these "contextual snapshots". Each snapshot included:
Company Summary: A concise description of the company, its sector, location, and approximate market cap.
Historical Trends: A CSV-formatted table of historical financial metrics, including company-specific data and macroeconomic indicators, like CPI, interest rates, and unemployment, over the past two years. This trend data was designed to highlight patterns over time.
10-K Summaries: Summaries of the risk factors, management discussion and analysis, and disclosures from the most recent 10-K report, distilled using LLMs via Amazon Bedrock.
@dataclass
class ContextualSnapshot:
year: int
q: int
company: Company
historical_trends: Dict[str, Trend]
future_projection: Projection
most_recent_10k_file: Optional[str] = None
def to_anonymous_report(self):
company_summary = self._get_company_summary()
historical_trends = self._get_historical_trends()
file_10k_extracts_summary = self._get_most_recent_10k_summary()
return f"""
# Company Summary
{company_summary}
# Historical Trends
{historical_trends}
# Most Recent 10-K Summary
{file_10k_extracts_summary}
"""
I saved each snapshot report to a markdown file, to be used as the primary input for the machine learning model in the subsequent phase. I also associated a set of labels describing the percentage change in the stock price over the subsequent quarter, six months, and year alongside each point-in-time snapshot.
Because, I was worried that a point-in-time sample for each company would not take into account financial announcements or would represent premature excitement from earnings reports, I took stock price samples using both the pre- and post-earnings stock prices for each of these time periods.
This data preparation phase was a little onerous, but it seems like worthwhile use-case to test the efficacy of applying modern language models to long context documents that mix both structured and unstructured data.
Model Training
With the data prepared, it was time to turn to training a model. For this phase I switched over my Sagemaker Studio instance to use a more powerful g6.xlarge GPU instance with an NVIDIA L4 GPU.
Choosing the Right Model Architecture
When it came to selecting a model, I knew I needed something that could handle the long context provided by the contextual snapshots. Older encoder only models with limited context windows and less pre-training would be insufficient, and newer encoder-decoder and decoder-only models were non-ideal for regression problems with the aim of predicting numeric values from contextual snapshot data.
I was therefore very happy when only a couple of weeks ago, Answer.ai and LightOn teams released ModernBert, a modern encoder-only mode which supported long context lengths.
Encoder-only models, like ModernBert, excel at understanding the context of long text sequences and converting them into meaningful embeddings. They use attention mechanisms to relate words within a large window. With its ability to process extensive texts, ModernBert was perfectly suited to handle the detailed contextual snapshots I'd created.
So, I swapped out my original llama-based fine-tuning with a ModernBert-large version.
Fine-tuning with QLoRA
Fine-tuning a transformer model with data with long context lengths requires significant compute. To efficiently fine-tune this model, I employed the use of QLoRA (Quantized Low-Rank Adaptation). QLoRA is a technique that enables us to fine-tune large language models efficiently using quantization and low-rank adapters. By quantizing model weights to 4 bits, and injecting small, trainable, parameters (adapters), we can drastically reduce memory consumption and train models faster.
Here's a brief snippet of my QLoRA code to show you how that works:
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
TrainerCallback,
BitsAndBytesConfig,
EarlyStoppingCallback,
ModernBertForSequenceClassification
)
from peft import LoraConfig, get_peft_model
import torch
def create_model(config: ModelConfig):
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model = ModernBertForSequenceClassification.from_pretrained(
config.base_model,
num_labels=config.num_labels,
problem_type="regression",
quantization_config=bnb_config
)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["Wqkv", "Wo"],
lora_dropout=0.1,
bias="none",
task_type="SEQ_CLS"
)
model = get_peft_model(model, lora_config)
return model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["Wqkv", "Wo"],
lora_dropout=0.1,
bias="none",
task_type="SEQ_CLS"
)
model = get_peft_model(model, lora_config)
Rolling Window Training Strategy
Given the temporal nature of financial data, I employed a rolling window approach to simulate real-world conditions. I'd train the model using five years of historical data, and validate it on the subsequent year, moving the window forward by one year with each split. This was in an effort to try to maintain the model's relevance to current market dynamics.
def rolling_window_split(
df: pd.DataFrame,
train_window_years: int = 5,
validation_years: int = 1,
min_train_years: int = 3,
stride: int = 1
) -> List[Tuple[pd.DataFrame, pd.DataFrame]]:
years = sorted(df['year'].unique())
splits = []
# Calculate the total window size
total_window = train_window_years + validation_years
# Generate splits
for start_idx in range(0, len(years) - total_window + 1, stride):
train_start = years[start_idx]
train_end = years[start_idx + train_window_years - 1]
val_start = years[start_idx + train_window_years]
val_end = years[start_idx + total_window - 1]
train_df = df[
(df['year'] >= train_start) &
(df['year'] <= train_end)
]
val_df = df[
(df['year'] >= val_start) &
(df['year'] <= val_end)
]
if len(train_df['year'].unique()) >= min_train_years:
splits.append((train_df, val_df))
logger.info(f"""
Created split:
Training: {train_start}-{train_end} ({len(train_df)} samples)
Validation: {val_start}-{val_end} ({len(val_df)} samples)
""")
if not splits:
logger.warning("No valid splits were created with the given parameters")
else:
logger.info(f"Created {len(splits)} total splits")
return splits
Prediction Phase
By the end of this training process, I had a model capable of predicting company performance with some level of accuracy (a root mean squared error of around 20-30%), so I used the trained model to generate a set of predictions for each stock in my dataset.
def predict(self, df: pd.DataFrame, batch_size: int = 3) -> pd.DataFrame:
df = get_latest_files(df)
dataset = DynamicTextDataset(df, self.tokenizer, self.config.max_length)
dataloader = DataLoader(dataset, batch_size=batch_size, collate_fn=collate_fn)
predictions = []
metadata_list = []
self.model.eval()
with torch.no_grad():
for batch in dataloader:
outputs = self.model(
input_ids=batch['input_ids'].to(self.device),
attention_mask=batch['attention_mask'].to(self.device)
)
predictions.extend(outputs.logits.cpu().numpy())
metadata_list.extend(batch['metadata'])
results_df = pd.DataFrame(metadata_list)
results_df['predictions'] = predictions
return results_df
But predicting a company's stock price to within 20%-30% margin of error is not useful in itself. After all, a company's stock price depends on far more than the small sum of information available within a contextual snapshot.
Ranking Stocks
I wanted to understand which companies the model would give an edge to compared with the other companies. As such I built a simple ranker.
Ranking Algorithm
I used the simplest ranking approach I could. I took the stock price pre-earnings and post-earnings for each of the next-quarter, next six-months, and next year. I then ranked growth of each company over each time period. Lastly, I combined the rankings, weighting the year change at 0.5, the six month change at 0.3, and the quarter change at 0.2.
Here's the code for my ranker if you're interested:
class FinancialRanking:
def __init__(self, weights: Optional[Dict[str, float]] = None):
"""
Initializes the FinancialRanking class.
Args:
weights (Dict[str, float]): Weights for different prediction periods
Default: {"next_quarter": 0.2, "next_six_months": 0.3, "next_year": 0.5}
"""
self.weights = weights or {"next_quarter": 0.2, "next_six_months": 0.3, "next_year": 0.5}
if not np.isclose(sum(self.weights.values()), 1.0):
raise ValueError("Weights must sum to 1")
def _combine_ranks(self, row: pd.Series, method: RankCombinationMethod) -> float:
"""
Combines per-period ranks into a single score.
Args:
row (pd.Series): Row containing period ranks
method (RankCombinationMethod): Method to combine ranks
Returns:
float: Combined rank score
"""
ranks = [
row['next_quarter_rank'],
row['next_six_months_rank'],
row['next_year_rank']
]
if method == RankCombinationMethod.AVERAGE:
return np.mean(ranks)
elif method == RankCombinationMethod.MINIMUM:
return np.min(ranks)
elif method == RankCombinationMethod.WEIGHTED_AVERAGE:
return (
ranks[0] * self.weights['next_quarter'] +
ranks[1] * self.weights['next_six_months'] +
ranks[2] * self.weights['next_year']
)
else:
raise ValueError(f"Unsupported rank combination method: {method}")
def rank_stocks(self, df: pd.DataFrame, combination_method: RankCombinationMethod = RankCombinationMethod.WEIGHTED_AVERAGE) -> pd.DataFrame:
"""
Ranks stocks based on predictions using the specified combination method.
Args:
df (pd.DataFrame): DataFrame with predictions column containing arrays of predictions
combination_method (RankCombinationMethod): Method to combine period ranks
Returns:
pd.DataFrame: DataFrame with added ranking columns and sorted by final rank
"""
# Convert predictions to numpy arrays if they aren't already
df = df.copy()
df['predictions'] = df['predictions'].apply(lambda x: np.array(x) if not isinstance(x, np.ndarray) else x)
# Create ranking dataframe for each prediction period
prediction_df = pd.DataFrame({
'ticker': df.index,
'next_quarter': df['predictions'].apply(lambda x: np.mean(x[:2])),
'next_six_months': df['predictions'].apply(lambda x: np.mean(x[2:4])),
'next_year': df['predictions'].apply(lambda x: np.mean(x[4:]))
})
# Calculate ranks for each period (higher predictions get lower ranks)
prediction_df['next_quarter_rank'] = prediction_df['next_quarter'].rank(ascending=False)
prediction_df['next_six_months_rank'] = prediction_df['next_six_months'].rank(ascending=False)
prediction_df['next_year_rank'] = prediction_df['next_year'].rank(ascending=False)
# Calculate combined rank
prediction_df['combined_score'] = prediction_df.apply(
lambda row: self._combine_ranks(row, combination_method),
axis=1
)
# Add ranks back to original dataframe
df_result = pd.concat([
df,
prediction_df[['next_quarter_rank', 'next_six_months_rank', 'next_year_rank', 'combined_score']]
], axis=1)
# Sort by combined score and add final rank
df_result = df_result.sort_values('combined_score')
df_result['rank'] = range(1, len(df_result) + 1)
return df_result
The Initial Results
Some important Caveats
In this experiment, I didn't deal with many edge-cases where my data extraction failed, or where I wasn't able to find some mappings for company ciks and tickers, or where there were transient network failures. I also stopped early. A full list of 3000 stocks from the Russell 3000 was too many for me, so when I had enough training examples, I just stopped there. As such, I only ran training and inference on a subset of the Russell 3000. Nonetheless, I processed larger companies first so many of the more stable results will be well represented with in these findings.
A second caveat, while I am a reasonably proficient dabbler in machine learning, I am hardly an expert.
A third caveat, I am not recommending that you invest in this approach. Hedge funds are working full-time trying to outdo my strategies, and I expect there are probably far better ways of achieving high yield than this. If you choose to copy my trades and lose your money because of it, don't come crying to me.
Lastly, this is less of a trading project and more about having fun. So I hope you found this to be as fun a read as I found it an experiment.
With caveats out of the way, here are the rankings:
The Rankings
Here are the top 20 and bottom 20 companies out of my sample of 608 snapshots that the fine-tuned model tends to like:
The Top 10
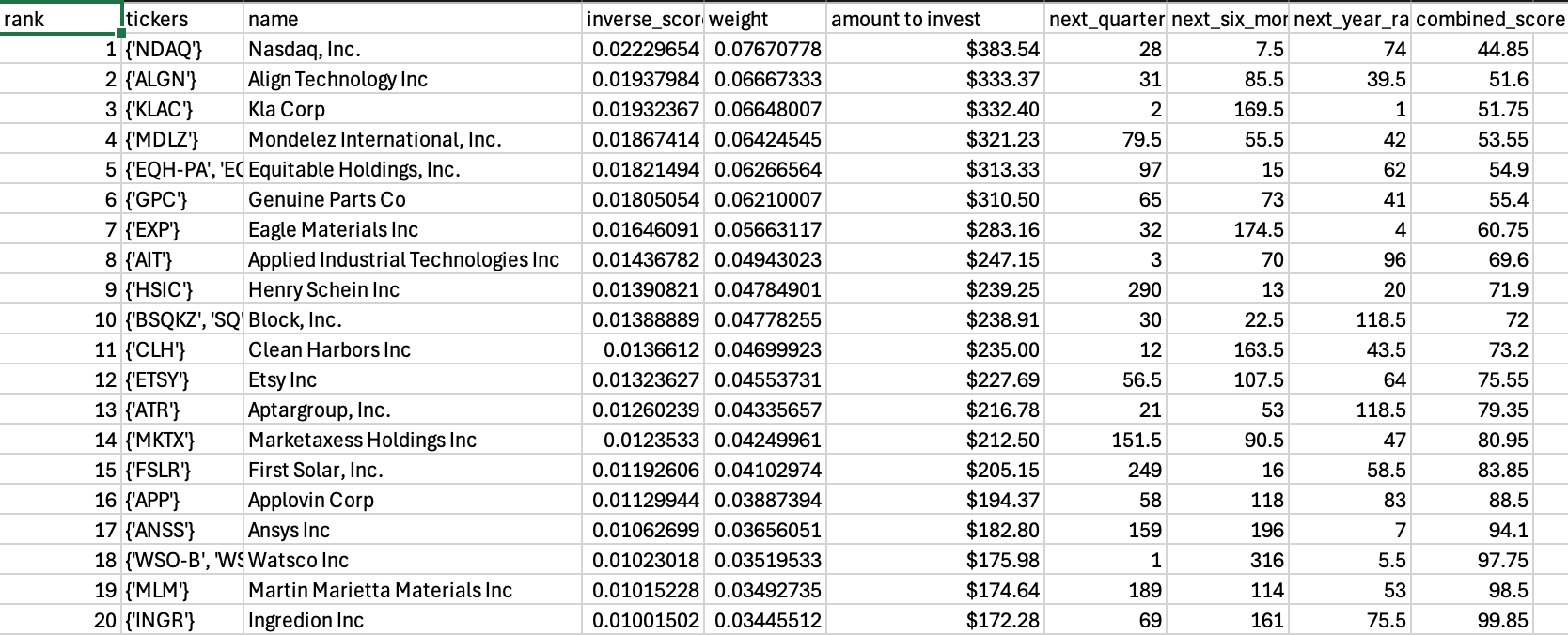
Why did the model like these companies' recent snapshots? I don't know. After all, I still know very little about finance. I will say that sampling them and feeding them to a non-fine tuned Claude didn’t yield a ton of excitement from Claude. Additionally, most of these stocks have underperformed for at least the last few months. I will nonetheless be entrusting my money’s fate to the hands of this model and we’ll see why it likes them so much.
Whether or not there is enough signal in the model to help beat the market is something we will only find out a year from now.
The Bottom 20 stocks
I’m not so confident in this model that I’m shorting these stocks, but here is what my model disliked the most.

Conclusion and Next Steps
This whole experience highlights the power of combining the ability to buy GPU time on demand from AWS, a crazy idea, and all the new AI/ML tools both open source and paid that are on the market today. While predicting stock prices precisely is unrealistic, leveraging the knowledge extraction and reasoning capabilities of large language models, combined with a focus on relative stock performance has the potential to give us a meaningful edge over simply picking stocks at random.
Just how much of an edge? Well that's is where the real fun begins. I’m investing $5,000 in the top stocks chosen by my model.
I created a Public account to track the performance of my stocks which you can follow along with here. This account takes the top 20 stocks from the model and purchases them in inverse proportion to their combined score which is a score that shows the strength of their rank for each of those three time periods weighted toward the end of the year. I placed orders for the corresponding amounts rounded to the nearest dollar at Public that should be fulfilled at the start of trading tomorrow.
Follow along over at: https://public.com/@yehudac
A year from now, (if I remember), I'll share the results here.
There are many other domains other than finance where similar approaches might prove even more value. If you’d like to read the code for this project or try run it for yourself, you can visit my github repository here.
Acknowledgements
Before I leave you, I'd like to make a few acknowledgements:
I'd like to thank the AWS Community Builders program for providing the compute credits that have enabled me to undertake this project. I made extensive use of Sagemaker Studio Notebooks, Bedrock, and the GPUs over this course of time.
I'd also like to thank the authors of the open source tools used in this project. Head over to their Github profiles and give them some stars because stars like them make this kind of tinkering possible.
I'd like to thank Jeremy Howard for his fast.ai course of which I completed several lessons when first exploring machine learning. I'd also like to thank him and his team for continuing to release open source powerful tools like ModernBert which I and many other tinkerers deeply appreciate.
Lastly, I’d like to thank my artificial buddies Claude 3.5, ChatGPT, and Google Gemini 2.0 Flash Experimental, who have helped me with some ad-hoc questions along the way and have also helped me review this blog post.