A comprehensive guide to communication in distributed systems with AWS
Part 1 of 2: How push and pull-based communication architectures are used with synchronous and asynchronous services

Since starting my career in software engineering around eight years ago, I have been a little obsessed with distributed, and event driven systems. This blog post is the first of two in an attempt to formalize some of the fundamentals I have learned along the way. Although the concepts I discuss herein apply generally, I use AWS communication services to help illustrate these concepts.
There is a lot of content I want to discuss here, and so I have broken it up into two parts.
This first section is entitled: How push and pull-based communication architectures are used with synchronous and asynchronous services.
This first part addresses the following:
Understanding and visualizing lambda invocation approaches
Push-based, asynchronous APIs
Comparing pull-based and push-based communication models
Comparing pull-based communication vehicles
Queues
Streams
The second section is still in progress and is entitled Organizing and integrating services and I will try to publish it over the next couple of weeks. The second section addresses:
Delivering a single message to multiple destinations
Rule-based delivery of messages to multiple consumers
Orchestrating and choreographing complex workflows
Event-driven choreography
Engine-driven orchestration
Without further ado then:
How push and pull-based communication architectures are used with synchronous and asynchronous services
A couple of months ago, I came across a very interesting and all-around excellent analysis published by Luc van Donkersgoed: Serverless Messaging: Latency Compared.
In this blog post, Luc experiments with lots of different mechanisms of triggering a lambda function. He measures the average time taken from the time a message is sent until it a lambda function is triggered across a sample of these mechanisms.
Message latency is, however, but one of the factors to consider when selecting a method of communication for your integration.
In Luc’s analysis, a column of the results table is dedicated to indicating whether an AWS service integration with Lambda is pull-based or push-based. Later on in the analysis, Luc explains the difference between pull-based and push-based lambda integrations:
In our Lambda-to-Lambda setup a push-based messaging system will invoke our Consumer Lambda Function for us.
and:
In a pull-based system like SQS or Kinesis, a message is placed onto a queue or stream, from where it can be retrieved by a consuming system.
Queues and streams, are the two primary pull-based transport vehicles for most distributed systems. SQS allows you to create managed queues, and Kinesis allows you to create managed streams.
There is nonetheless a subtle but important distinction between a push-based service integration and a push-based communication paradigm.
You see, while a pull-based service integration necessitates a pull-based communication paradigm, the converse is not true. A push-based service integration can provide an interface that encompasses two steps:
Placing a message into a pull-based communication vehicle.
Performing the work with an idle worker process that pulls the message off the queue.
Luc therefore includes another column in his results table indicating synchronous or asynchronous invocation. An asynchronously invoked lambda function abstracts over its message queue integration, but the workers still pull the task from a queue internal to the lambda service.
There are therefore three ways to invoke a lambda function:
A synchronously invoked lambda where the lambda is invoked in a push-based model, and where the response is returned synchronously.
An event-source mapping, where the lambda is configured to listen to a pull-based event source.
An asynchronously invoked lambda function that abstracts over its message queue integration. In this model, workers still pull the task from a queue, but the queue is internal to the lambda service.
Different AWS services integrate with Lambda differently per the following grid:

Understanding and visualizing lambda invocation approaches
To further illustrate the distinction, I have drawn three diagrams:

Note that in this Diagram 1, a message store is external to the service. The service is configured to pull messages from the external message store. This model is an approximation of how the Event Source Mapping Invocation model within AWS Lambda operates. External event sources that Lambda will poll for work include:
SQS queues (FIFO and regular)
Kinesis streams
DynamoDB streams
Amazon MQ queues
Kafka streams
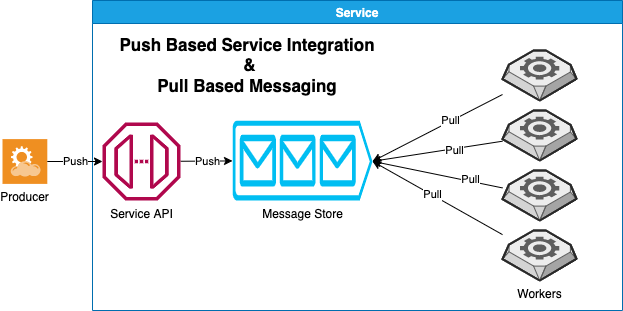
This is incredibly similar in structure to the way that asynchronous lambda invocations work from a messaging standpoint. In Diagram 2, shown below, messages are pushed to a message store, and workers pull from the message store. This process is almost identical to the flow in Diagram 1. The difference is that the message queue is local to the Lambda Service rather than external. The Lambda service abstracts the message passing process away from the event producer.
The final integration model for Lambda is the one that is probably most familiar to most people. This is true because it is arguably the communication model that maps most intuitively to interactive experiences. We send requests directly to an application worker that is waiting for us to send it work. It completes the work, and responds with the result. This application worker is therefore appropriately named an application server. A typical push-based client-server messaging model with an API layer and a load balancer is illustrated below in Diagram 3:

Push-based asynchronous APIs
It is true that when AWS’ Lambda functions are invoked asynchronously, a message queue intermediary is always used. This is a design decision made within the Lambda service, but not all asynchronous services require a message queue or pull-based messaging.
Webhook endpoints, for example, represent non-blocking asynchronous communication patterns that are nonetheless push-based. As soon as a webhook is invoked, a new thread can be spawned to handle the event. This is illustrated in Diagram 4:

In these scenarios, clients do not need to remain blocked while waiting for a notification from the server. This is in spite of the fact that no pull-based transport vehicles were used in the communication process.
This API represents an asynchronous, but push-based API implementation absent the use of a message queue.
For reasons that we will discuss, although services of this nature are possible, it is incredibly common to write messages received at a webhook endpoints to a message queue. This change in architecture is illustrated in Diagram 5:

Notice how the load balancer behind the webhook API has been replaced with a message queue. Also notice, that this second webhook API messaging architecture resembles the same architecture used in asynchronous lambda function invocation.
Comparing pull-based and push-based communication models
At this point, you should clearly understand the concepts of push-based and pull-based communication. Let’s understand some of the tradeoffs you make when you select a communication model across a set of dimensions.
Simplicity
Push-based communication models are simpler than pull-based communication models. Effectively, only two components need to be present: a client and a server. The server listens for requests, the client sends a request to a server, the server handles the request and sends the response back to the client.
In the case case of a pull-based communication model, a third component is introduced: a transport vehicle usually in the form of a message queue or a stream.
A producer places a message in a queue or a stream. A worker polls the queue or the stream for tasks it can perform. This creates indirection and the request path changes.
The transport vehicle is not the only complexity introduced, however. After the worker performs the work, the result may need to be relayed back to the caller which might require the caller to listen to event streams.
On top of the actual communication complexity added, adding a message queue makes tracing requests as they flow through our system more difficult. We often need to be able to understand where a request is along its journey. With requests being queued, consumed, and chained together this becomes more and more difficult. This usually results more urgent need to implement monitoring solutions, along with increased operational and implementation complexity.
Complexity is something I like to avoid wherever possible, and if simplicity were the only dimension in question the decision would be simple: no pull-based communication, just push-based communication.
Latency
Latency is a difficult dimension to unpack, because different system conditions, implementations, and resource congestion can result in pull-based or push-based communication models winning the race.
With that said, assuming underutilized compute, memory, and network resources, I would expect additional network and disk hops along with slower polling intervals to make pull-based slightly slower than client-server push-based communication. With that said, the impact of these hops should be small in a well-designed distributed system. It is still very much possible to achieve realtime and interactive experiences using pull-based request models.
Looking at Luc’s analysis table linked above that compares lambda triggers from a latency perspective unfortunately yields little insight into this problem. One cannot generalize general performance in pull-based architectures from AWS Lambda triggers, because each integration is service specific. Each integration abstracts over enough functionality that it is impossible to know how much of its latency is introduced by the presence of a queue or stream.
Reliability
When I started my first job as a Software Engineer after college, I remember hearing the constant refrain that message queues are more reliable than synchronous APIs. In my youthful naivety, I doubted the validity to this philosophy. After all, to my mind, an extra hop in the network represented an extra failure scenario.
The services I had used at the time seemed pretty reliable, and I didn’t understand why an invocation writing a message into a queue had any more chance of succeeding than calling the service directly.
I have since become older and less naive. Not all services are equally reliable.
The bottleneck in push-based communication is usually the performance of the application processing the input from the TCP backlog queue. The more dependencies an application has and the more complex the work performed, the slower the service will be able to process the incoming requests. This might be due to memory or CPU or disk or network bottlenecks. As each server is overwhelmed, user experiences will experience higher and higher latency, or the application might crash entirely.
When you are dealing with very simple services with few dependencies that execute quickly with little resource consumption, this will usually not be an issue. Requests get handled quickly and cycle through the system quickly. If you are seeing huge request volumes, you simply scale your backend horizontally and use a load balancer to distribute load across the available servers. If a servers’ resource utilization starts to take strain, simply add more capacity.
A synchronous service that places one or more messages or events in a queue or stream is a simple service with very few dependencies. No data transformations occur. Data is persisted. Very few services are as simple a queue or stream interface, and so the chance of a message not making it to a queue or stream is very very small.
The more resource intensive a service or the more dependencies it has, or the more time a request takes to process, the higher we can expect the failure rate to be. Most service processes will therefore be far less reliable than writing to a message queue or stream.
One function of pull-based communication vehicles is to decouple systems. This is an often repeated mantra in marketing materials used to sell message queues and streams.
The advantages of decoupling systems are sometimes described as primarily impacting service flexibility. The theory goes that a producer can be wholly unaware of a consumer. A consumer can be wholly unaware of its producer. Each service need only be aware of message queue in order to operate. Indeed, this interpretation is the interpretation given in Apache ActiveMQ documentation linked above:
The senders and consumers of messages are completely independent and know nothing of each other. This allows you to create flexible, loosely coupled systems…
…Using a message bus to de-couple disparate systems can allow the system to grow and adapt more easily. It also allows more flexibility to add new systems or retire old ones since they don't have brittle dependencies on each other.
I disagree with this characterization entirely. Flexibility of systems is achieved through clearly defined API / Endpoint contracts, not through the use of message queues. Even in queue based systems, it is important to define contracts. If a producer suddenly starts submitting messages with a changed structure, or a consumer suddenly starts requiring a field that used to be optional, inserting a message queue is not going to fix broken integrations.
If you have well-defined API interfaces and service contracts, the API implementation can easily be replaced or modified. This is true for pull-based and push-based communication models alike.
My understanding of the benefits of using pull-based communication models to achieve decoupling of services is different. It pertains far more to reliability and fault-tolerance than system flexibility. AWS SQS marketing copy provides this great description:
SQS lets you decouple application components so that they run and fail independently, increasing the overall fault tolerance of the system.
Pull-based communications let you design more reliable systems because if a consumer believes it is too busy to pick up a new request, it can simply leave it in the queue to be picked up by another consumer or to wait until it has capacity to service the request.
The more resource intensive a service, the more dependencies a service has, or the more time a request takes to process, the more using a pull-based communication vehicle reduces the risk of system failure.
I like to use the following analogy to describe the reliability benefits gained by pull-based over push-based messaging:
Tom the juggler is performing in front of an audience. Tom is requesting that audience members give him objects to incorporate into his juggling act. Should Tom request that the audience toss their items to him, or should he request that they place it on a table for him to pick up?
Think of placing objects on the table as placing objects in a queue. Think of tossing objects to the juggler as using a regular synchronous, push-based application server. I, for one, hope that nobody in the audience tosses a chainsaw to the juggler.
Durability
While durability sounds like a similar metric to reliability, there is a subtle but important difference. Reliability describes how likely it is that the system fails. Durability describes how resilient the service is in failure scenarios. This is a key component of fault-tolerance.
If a producer places a message into a message queue or a record into a stream and a consumer is experiencing an outage at the time, there is no harm caused. When the consumer is repaired, it can pick up where it left off and process a backlog of messages or records.
Message queues and streams both typically retain messages and records in failure scenarios. We will discuss how different failure scenarios are typically handled with each of streams and queues in a comparison later on.
In push-based communication models when requests fail, the client needs to become aware of these failures. Once a client is aware of these failures, simply retrying might result in additional failures, so protocols need to be established to determine when and how and to retry requests. These protocols might or might not be reliable or need to change over time. They will certainly result in significant complexity in client code.
Or, the consumer can simply introduce a pull-based communication vehicle to decouple it from the producer. In this way, even if the consumer fails, no further input from the producer is required to recover. The recovered consumer can simply go back in time and process the requests that are backlogged in its pull-based communication vehicle awaiting processing.
Cost
Relative to most services message queuing and streaming services are usually very cheap. As such, to understand how pull-based communication vehicles affect system cost, we must investigate how resource utilization changes as an integration model changes from push-based to pull-based.
We mentioned above that, a consumer can decide when to pull a request off a queue, but a server cannot decide when to process a request from a user. This means that if we want to ensure that a push-based service is stable, we must over-provision capacity to handle the requests. After all, who knows when or how big the next request is going to be. Even if a system is idle, push-based message models require enough capacity to handle a sudden influx of large requests.
In the case of pull-based request models, because a consumer can elect when to process a message it is possible to achieve far greater utilization of resources. After all, if a sudden influx of large requests comes in after some idle time, they will be queued, and more capacity can be added to the system to process them, or the backlog will slowly be drained during other idle periods.
For services where influxes of large requests are common, pull-based strategies enable the maximization of allocated resources.
A Summary
Processes which are long running, or are resource intensive, or have many dependencies become far easier to implement reliably, durably, and cost effectively leveraging streams or queues.
Although, pull-based communication vehicles introduce another hop in a request’s journey, they do so with specific goals in mind. I, for one, do not know if it is possible to achieving reliability, durability, and cost-effectiveness for the classes of services that we have identified without using a stream, queue, or analogous pull-based replacement.
Comparing pull-based communication vehicles
Streaming and queueing systems both typically provide a pull-based communication vehicles for passing data. The similarities end there. Each queues and streams are designed to solve a set of distinct challenges.
Queues
Queues can be thought of as ordered backlogs comprised of work that must be performed. Each message in a queue represents a segment of work intended for a single consumer or worker. Which consumer, you ask? Why whichever one is able to get to the work first.
When a worker pulls a message off of a queue, the message becomes invisible, or locked so that other workers do not work on the same message concurrently.
If a worker fails to process a message, or in some implementations if a worker times out, the message becomes available to other workers for processing. If multiple workers fail to process the same message, queuing systems usually support a mechanism of quarantining that message so that it does not clog up the workers by moving them to a dead-letter queue. This dead-letter queue can deliver messages to error handling processes.
AWS has two queue services that provide queues, Amazon SQS and Amazon MQ which provides managed solutions for RabbitMQ and ActiveMQ.
Streams
Streams maintain a persistent, ordered view of data records. Unlike queues, when consumers read records from a stream, they remain in place and visible to other consumers.
In stream-based architectures, consumers are responsible for keeping track of what messages in the stream they have processed and maintain a cursor to the most recently processed message. This property enables multiple types of consumers to process the same stream in parallel.
Because streams are not simply a backlog of work, they offer no locks or dead-letter messages and when consumers have processed records they do not delete them from the queue. This leaves consumers with the responsibility of implementing fault-tolerance themselves. In stark contrast to queues, streams do not support visibility timeouts or message locking.
One of the other key differences between queues and streams is that messages in a queue are intended to be processed independently. One message never needs to be processed alongside a second message. Streams on the other hand index every item and data is often processed in time-windows. Multiple records within a window are often aggregated and processed to provide real insights over sequenced data.
This property of streams makes them quintessential components of many realtime analytics architectures, and streams therefore provide APIs to query messages in bulk. Stream processing frameworks like Apache Spark have been built to enable complex aggregations over data within streamed records using familiar data query languages like SQL.
Because streams let you pull huge volumes of data at a time, and because retrieving that data does not perform any distributed locking, you can often improve processing performance tremendously by switching from a queue worker to a stream consumer when processing huge volumes of data.
Several Amazon services expose provide streams. Amazon provides its own Kinesis Data Streams and Amazon MSK provides a managed Kafka solution. DynamoDB record changes can also be configured to reactively emit to dynamodb streams.
A Summary of Part 1
Streams and queues are both very useful components when attempting to define pull-based architectures, but they target different use-cases. Streams were created to enable consumers process sequenced data in bulk without overwhelming consumer, while queues exist to distribute work across a series of parallel workers without overwhelming any worker.
In AWS, you will notice that Lambda Polling is available for all service integrations for SQS, AmazonMQ, DynamoDB Streams, Kinesis Streams, and Managed Service for Kafka streams.
Queues and streams are very powerful components that empower your architecture when designing pull-based solutions.
If your service calls are short and simple CRUD (Create, Read, Update, and Delete) operations, you are better served with a push-based communication services like AWS API Gateway, Cloudfront, and AWS Elastic Load Balancers.
This isn’t the end of the story, however. We also have other very powerful abstractions that let us compose, fan out, and use rule-engines to orchestrate and choreograph complex distributed processes. Part two of this blog series is coming soon and is focused on Organizing and Integrating Services.
Great write-up. We also recently published an article on how to bridge Backend and Data Engineering teams using Event Driven Architecture - https://packagemain.tech/p/bridging-backend-and-data-engineering